


晓多科技推出的新语言模型Xmodel-LM——一个紧凑高效的11亿参数(1.1B)模型,预训练于超过2万亿个token的数据集之上。它的特点在于,不被较小的模型规模所局限,展现出与现有开源语言模型相似或更优的性能。作为一个GPT类大语言模型,Xmodel-LM不仅仅是一个文本生成器,它能在各种任务中表现出色,比如帮助电商客服更准确地理解客户的需求,或者在内容创作领域为创作者提供灵感。
在我们的日常生活中,GPT类语言模型随处可见,但你真正了解它吗?
模型架构
Xmodel-LM采用了与LLaMA 2类似的模型架构:
1.RoPE(旋转位置嵌入)
就像是一个魔法箭头,每个单词都会有一个根据位置转动的箭头,告诉你它在书中的具体位置,让每个单词都在特定的页码和位置上,这样你的大脑(模型)就能更好地理解整个故事的顺序和内容。
2.RMSNorm(均方根归一化)
如果说搭建大模型是把积木堆成一座高塔,那么RMSNorm就像是一个魔法工具,它确保每一层的积木(模型的一部分)都有差不多的重量(输出),让整个塔(模型)更加稳定,不容易倒掉。
3.SwiGLU(激活函数)
把原来用的ReLU这个“发动机”换成了SwiGLU,这个新的“发动机”能让模型性能更优,在处理复杂问题时更有力、更高效。4.GQA(分组查询注意力):就像是给模型的大脑装了一个多任务处理器,让它能够同时处理大量信息,而且处理得更快、更有条理,提高了模型处理信息的速度和效率。通过这些技术的结合,Xmodel-LM模型不仅变得更聪明、更稳定,而且处理信息的能力也大大提高了。

如何训练Xmodel-LM
在构建训练语料库和分配权重的过程中,晓多科技的主要目标是确保训练数据的质量和多样性。
首先是“预训练”,在大量的文本数据上进行无监学习,让模型学习语言的统计规律和语义表示。Xmodel-LM的原始数据集主要由其他LLMs的聚合训练数据组成,为了解决训练数据分布中书籍和数学数据分布的不足,晓多科技还纳入了FanFics和OpenWebMath。此外,添加了中文数据源PTD和WanJuan,以赋予模型一定的中文熟练度。通过这些精心准备的训练材料,Xmodel-LM在学习过程中全面而均衡的发展,成为一个多才多艺的语言学习高手。
其次是“微调”,依靠AdamW优化算法来调整学习过程,确保了学习效果的最优化。在预训练模型的基础上,使用特定的任务数据进行有监督学习,使模型能够更好地适应特定的应用场景。例如,在文本分类任务中,可以使用带有类别标签的文本数据对模型进行微调,使模型能够准确地判断文本的类别。最后通过一系列测试来评估Xmodel-LM的学习成果,让学习效果量化和可比较。
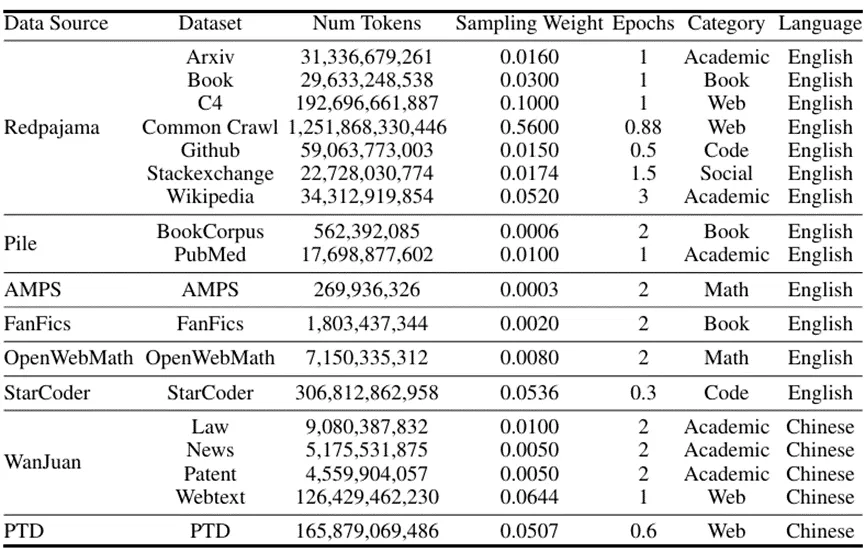
训练Xmodel-LM就像给学生挑选课本和参考书一样,训练数据集(Xdata)是晓多科技精心自建的,包括了不同来源的大量文本资料,剔除了重复和质量不高的内容,精心平衡了中文和英文的内容,以适应各种不同的语言处理任务。同时,Xmodel-LM还配备了分词器,可以理解为字典,与又大又厚的传统字典不同,它特别小巧高效,能帮助Xmodel-LM理解单词和短语,很好地处理中英文混合的内容。
Xmodel-LM的优势
规模小,性能强
晓多科技构建了完整的数据收集和处理的流程:基于开源数据生产了大量高质量、低重复且分布广泛的语料数据;基于Unigram方法和自采数据构建了体量较小但是压缩率高的分词器;基于本地环境对模型参数及架构进行消融实验,确定了最优训练参数。在训练完毕后Xmodel-LM模型性能达到同级别(1B)中的top,真正到了“小而强大”。

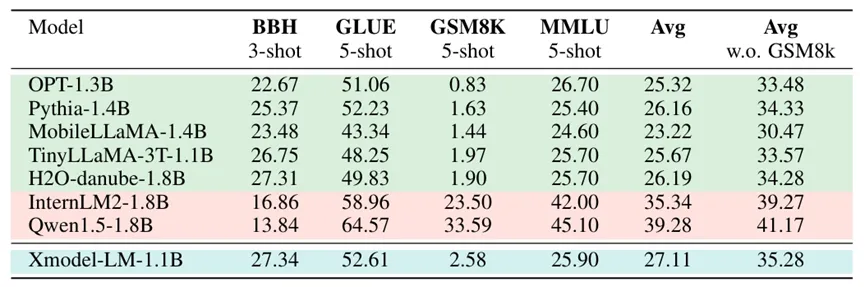
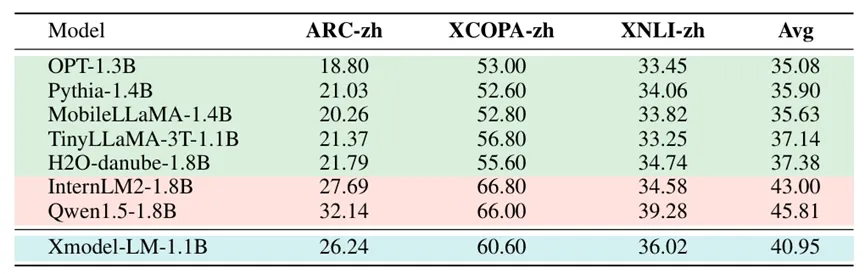
与MBZUAI和LiU两所大学共同研发的MobileLLaMA 1.4B、meta开源的OPT 1.3B等做对比,晓多科技的Xmodel-LM规模更小,不管是在常识推理评测、综合任务评测和中文能力评测方面,都表现得更优异,生成效果更优。与其他相似规模的模型相比,Xmodel-LM在多语言任务上展现出了竞争力,性能优于同规模的类似模型,在某些任务上超过了一些更大的模型,甚至在参数规模仅为他们的60%多的时候,性能也要更强。
成本低,质量高
晓多科技前段时间新推出的一种新型的多模态视觉语言模型Xmodel-VLM就是使用了这个轻量级的“大脑”——Xmodel-LM 1.1B,能够处理和生成语言,就像我们思考和说话一样。一个智能模型,拥有11亿个“脑细胞”,却能在家用电脑上轻松运行,不需要昂贵的超级计算机,更加亲民实用,在处理信息时更加敏捷高效。它在智能语言处理的世界里,以小搏大,展现出了令人难以置信的能力。
本模型为GPT类大语言模型,即基于Transformers-decoder堆叠而成的自回归语言模型,该技术路线相比其他路线有更好的文本生成能力,能够解决复杂场景下的问答、摘要等问题,高度契合我们面临的机器人客服应答场景:使用大语言模型的技术代替人工客服进行回复,通过基座和历史客服对话数据进行微调,可以保证在垂类领域中的可靠性,填补通用模型在专业知识上的不足,比如,我们的客服需要回答一些特别专业的问题,这个助手可以通过学习相关的知识,提供更加专业、可靠的答案。
与流行的开源模型中使用的广泛词汇表不同,分词器在中文和英文混合语料库上训练,词汇表大小仅为32,000。尽管词汇表较小,分词器依然在测试数据上展示了令人印象深刻的压缩率,这使得Xmodel-LM在保持小身材的同时拥有高性能。电商引入较小规模的大语言模型,可以降低在垂直类领域的应用成本,并且达到快速上线、快速应答的效果。
开源
Xmodel-LM的代码和模型已经在GitHub上公开,任何人都可以访问和使用这项技术,这为语言模型的研究和应用开辟了新的可能性。
应用场景和未来展望
Xmodel-LM这样的智能模型,正在悄悄地改变我们的世界。它使用自建数据集平衡中英文语料,针对下游任务进行了优化,可以应用于各种自然语言处理任务,如文本摘要、情感分析、机器翻译等。它们让在线购物更加智能,让写作更加高效,甚至可能催生全新的商业模式。综合应用场景有以下几点:
- 语言处理与翻译:能够理解和生成中英文文本,适用于实时翻译、多语言内容创作和跨文化交流。
- 智能助手与客服:可以提供个性化服务、自动化回答用户问题,并在客户服务中提供多语言支持。
- 教育与学习工具:模型可以辅助语言学习、提供知识点讲解和练习,成为教育领域的辅助工具。
- 内容分析与生成:能够分析文本内容,提取信息,并自动生成摘要、报告或创意文案,适用于新闻、媒体和企业文档处理。
- 技术与研究辅助:在软件开发、编程辅助、数据分析和学术研究中,Xmodel-LM可以提供技术文档理解、代码生成和研究资料整理等功能。
晓多科技作为服务营销数智化解决方案专家,研发的Xmodel-LM在客服应答领域有不俗的表现:能够理解用户的问题并提供即时的答复,可以代替传统人工客服,提供24/7的不间断服务,处理订单问题,解答用户咨询,比如商品详情、促销活动、订单状态等,减少客服压力;自动生成商品描述、促销文案等,节省人力成本,保持容的新颖性和吸引力;对于跨国电商,Xmodel-LM可以支持中英两种语言,未来还将掌握更多的语言,帮助商家更好地服务不同语言的消费者;通过对消费者评价和反馈的分析,Xmodel-LM还可以帮助商家了解消费者的情感倾向,从而优化产品和服务。这种高效的服务模式不仅能够提升用户满意度,还能够降低企业的运营成本。
晓多科技未来将继续对Xmodel-LM进行开发升级,让它可以优化电商平台的搜索功能,理解用户的搜索意图,提供更准确的搜索结果;根据用户在网站上的行为模式,分析用户的历史购买记录、浏览行为和偏好,帮助商家了解用户的需求和偏好,生成个性化的商品推荐,提高用户的购买转化率。
结语
小型模型也能拥有巨大潜力,Xmodel-LM在智能客服、教育辅助、内容创作等多个领域展现出强大的应用能力。随着技术的不断进步和应用的不断拓展,晓多科技将开启智能服务的新篇章,引领我们走向一个更加智能、高效、个性化的未来。在未来的道路上,晓多科技将继续进行AI技术的创新,不断探索和实现人工智能在各行各业的深度融合与应用。用智能点亮生活,用创新引领时代。
感谢您体验Xmodel-LM的探索之旅。如果您想了解更多,请访问Xmodel-LM的代码仓库。
——晓多科技,与您一起,智绘未来。
点击此处查看论文!!!
原创文章,作者:晓多AI,如若转载,请注明出处:https://www.xiaoduoai.com/blog/15241.html